
Credit card fraud is a major problem in the financial industry. Fraudulent transactions can cause significant losses for both cardholders and financial institutions. However, detecting credit card fraud is a challenging problem, especially when the data is imbalanced. This means that the number of fraudulent transactions is much lower than the number of non-fraudulent transactions.
In this blog post, I will demonstrate how to detect credit card fraud using the random forest algorithm. I will compare the performance of the model when trained on imbalanced data versus oversampled data.
You can find the Python implementation here and the credit card dataset can be downloaded here.
Exploratory analysis
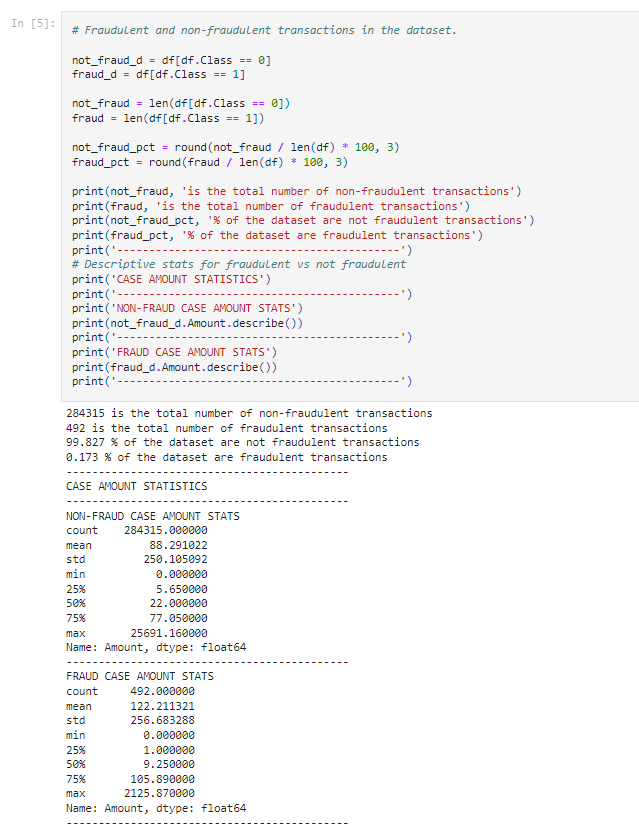
When analysing the data with descriptive statistics it is immediately clear how imbalanced the dataset is in favour of non-fraudulent transactions:
Evaluation Metrics
Before diving into the details of the model, it’s important to understand the evaluation metrics used to assess the performance of the model. In this case, the following metrics were used:
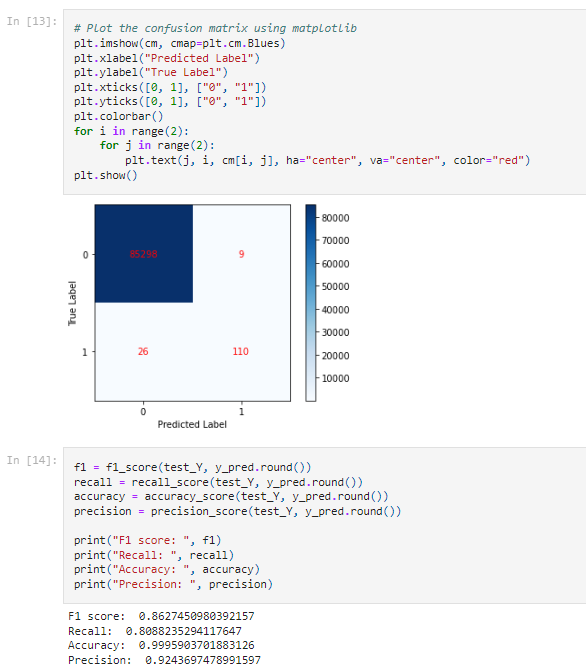
- F1 score: The harmonic mean of precision and recall, a commonly used metric to balance the trade-off between precision and recall. A high F1 score indicates that both precision and recall are high.
- Recall: The ratio of true positive predictions to the sum of true positive and false negative predictions. It measures the ability of the model to correctly identify all positive instances.
- Accuracy: The ratio of correct predictions to the total number of predictions. It’s a simple but effective way to measure the performance of a binary classification model.
- Precision: The ratio of true positive predictions to the sum of true positive and false positive predictions. Precision measures the ability of the model to only predict positive instances when it’s actually a positive instance.
For more information on these metrics and the use of the confusion matrix to assess classification problems in Python consult this reference here.
Implementation with Random Forest
This demonstration uses the random forest algorithm, a widely used and effective machine learning algorithm, to detect credit card fraud. The random forest algorithm creates an ensemble of decision trees, where each tree is trained on a different subset of the data. The final prediction is made by combining the predictions of all trees.
The model is trained on the data, and the predictions are evaluated using the metrics described above. However, in this case, the original data is imbalanced, meaning that the majority of transactions are non-fraudulent. This can lead to a biased model, as it may have a high accuracy in predicting the majority class, but a low recall in detecting fraudulent transactions.
Oversampling with SMOTE
To handle the issue of imbalanced data, the Synthetic Minority Over-sampling Technique (SMOTE) method was used to oversample the minority class, the fraudulent transactions. SMOTE generates synthetic samples of the minority class to balance the class distribution.
The random forest algorithm is then trained on both the original imbalanced data and the oversampled data, and the results are compared. The results show that the use of oversampled data leads to an improvement in the recall of fraudulent transactions, which is a crucial metric in credit card fraud detection.

Conclusion
In this blog post, I briefly demonstrated proof of concept on how to detect credit card fraud using the random forest algorithm and compared the performance of the model when trained on imbalanced data versus oversampled data. I also explained the importance of evaluating the performance of the model using appropriate metrics, such as F1 score, recall, accuracy, and precision.
Oversampling with SMOTE is an effective method to handle imbalanced data, and it can lead to improved performance in credit card fraud detection. Other methods, such as undersampling, could also be used to handle imbalanced data, and the choice of method will depend on the specific problem and data at hand.
Overall, credit card fraud detection is a challenging problem, and the use appropriate of algorithms and methods is crucial to accurately identify fraudulent transactions.
Leave a Reply